How we work
This document provides an overview of GRCschema’s process for developing and changing GRC schemas.
Last updated
Was this helpful?
This document provides an overview of GRCschema’s process for developing and changing GRC schemas.
Last updated
Was this helpful?
This document provides an overview of GRCschema’s process for developing and changing GRC schemas.
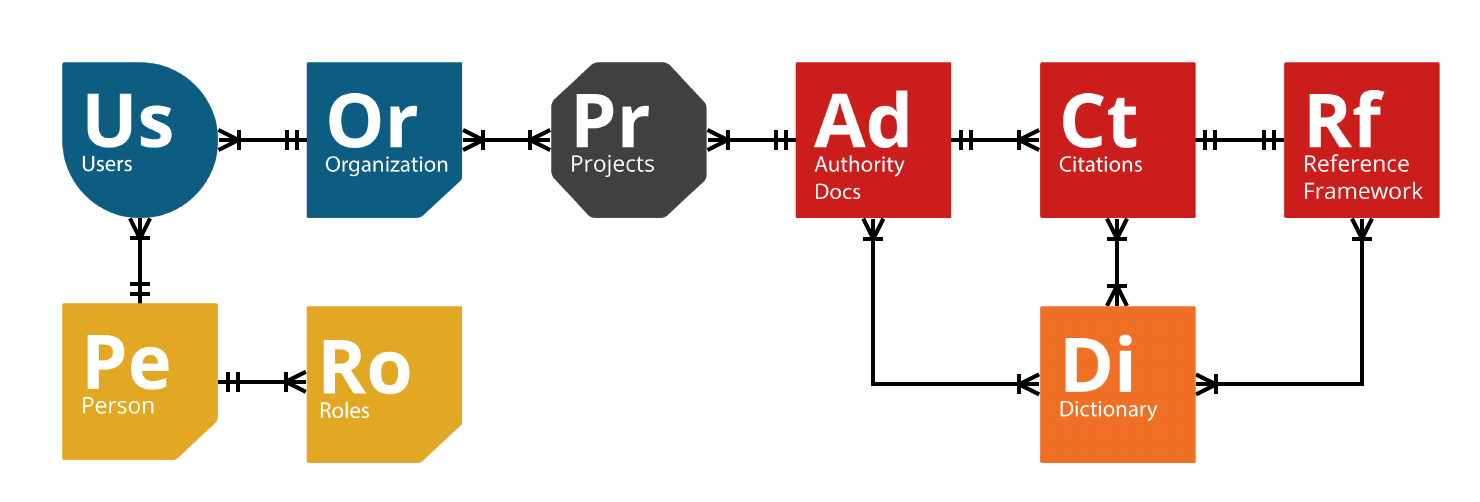
Each type can have one or more supertypes, although it is rare to have more than one supertype. This provides the main hierarchical navigational structure of GRCschema.org: a tree of types with each Thing at the root. A great example of this is shown below for the object:
There are four states to every object in the schema -
accepted - the proposed object is now accepted as a part of some release version.
withdrawn objects will be removed, but the documentation surrounding them will be maintained in the docs site.
NIST SP 800-70,
NIST’s Informative Reference Catalog,
NIST’s Open Security Controls Assessment Language (OSCAL),
TagVault.org’s Software Identification Tags (SWID Tags),
the Unified Compliance Framework, and
SIGLEX, a Special Interest Group on the Lexicon of the Association for Computational Linguistics?
GRCschema.org is a way of converging these together into a workable schema with a productive API back end that facilitates adding and extracting content from a central repository - irrespective of where the content came from. As schema objects get approved, they will be translated into API calls that are hosted on various API marketplaces. Anyone with a valid API key will be allowed to access the existing content.
English - its in English, and no it won’t be translated any time soon. If the explanations of an object aren’t clear, there’s a way for you to post a comment in the community. If a grouping isn’t clear - the same thing. If you want to suggest changes to a proposed object, you can do so in the voting process we have. If you want to copy the JSON-LD, its there for you. If you want to see it visualized, that’s there too for you to explore as you see fit.
proposed - a proposed change for any object is in the works. During this phase discussion about the object is in play. Discussions for each object can be found in the maintained by the UCF team (for now).
voting - the proposed object is now up for a vote. Each object up for a vote will be documented in GRCschema.org’s section. Each object up for a vote will have links for voting and seeing the status of the vote, as shown below:
Admittedly, the Unified Compliance team have several patents that read on this (see their patent page . If you are consuming or adding to the data via the forthcoming API, a Patent License Agreement and any payment for it is built in. If you so choose to not use the API and to build out the full data model shown on your own, you’ll need to sign the forthcoming Patent License Agreement. Because the full data model isn’t published yet, nothing is necessary at this time.


{kind=link}